- Email: biuro@kicb.pl
- Rondo Organizacji Narodów Zjednoczonych 1, 00-124 Warszawa

Prawdopodobnie mieliście już incydent bezpieczeństwa w naszej organizacji a jak nie, to może o tym jeszcze nie wiecie. Rozsądnie powinno się zakładać, że nie jesteśmy w stanie w pełni ochronić naszych zasobów. Możemy znacząco minimalizować ich utratę (np. zaszyfrowanie/modyfikacja, usunięcie) i czas do przywrócenia dostępności tychże danych.
Na stabilność takich rozwiązań wpływa wiele czynników, tutaj obierzemy tylko strategię odporności i odzyskiwania danych. Pominiemy m.in. opis planu procedur awaryjnych, innych zabezpieczeń na poziomie sieci, systemów, aplikacji i oczywiście edukacji użytkowników, jakichkolwiek bytów satelitarnych takich jak platformy observability, security teams czy procedur w organizacji. Pomijamy również złożoność sieci i jej skalowalność, infrastrukturę usług i zachodzące procesy dynamiczne.
Modele o wyższej gwarancji dostępności (np. z niższym współczynnikiem występowania awarii, z większą niezawodnością, z krótszym czasem przywracania dostępu do danych) wymagają większych zasobów, to może być: sprzęt, obsługa, licencje, złożoność technologiczna czy biznesowa, etc. Omawiamy rozwiązanie dostępne dla większości przedsiębiorstw.
Środowisko
Elementy wdrożenia to 2 bliźniacze serwery (poniżej) i klaster na długoterminowe archiwizacje. Serwery opisane są jako kvm107 (serwer 1) i kvm108 (serwer 2). Odrębna przestrzeń na archiwizowanie.
2 typy dysków: nvme i hdd
System operacyjnym modern linux
OpenZFS for Linux
Każde urządzenie posiada nośniki:
Karta PCIe RAID1 240GB
4 dyski nvme 960GB
8 dysków HDD 16TB
Infrastruktura na dane zimne (archive) to klaster Apache Hadoop https://hadoop.apache.org/ z usługami przechowywania danych – Hadoop Distributed File System (HDFS). Dane przechowywane są w nim za pomocą jednej z polityk Erasure Coding, a więc podziału danych na bloki i ich propagacji po różnych lokalizacjach (datanodach) w celu zapewnienia odporności na awarie. Pozwala to zaoszczędzić dużo przestrzeni dyskowej jednocześnie zachowując przyzwoity poziom bezpieczeństwa. Więcej opisałem na blogu https://bigdatapassion.pl/blog/devops/differences-between-erasure-coding-and-replication/.

Na karcie PCIe znajdują się 2 sloty na dyski i każdy ma pojemność 240GB. Karta obsługuje sprzętowo m.in. tryb RAID1 (mirror) i jest wykorzystywana do startu OS. Odpowiednikiem takiej karty np. dla serwerów Dell to Boot Optimized Server Storage (BOSS).
Na pozostałych dyskach utworzone są 3 pule o nazwach z1 z2 i z3.

Pula z1 to przestrzeń do utrzymywania niewielkich obrazów dysków systemów wirtualnych maszyn. Znajdują się tutaj zainstalowane aplikacje, dane są przechowywane w z2.

Na z1 każdy zasób odpowiada jednej lub większej ilości usług, aby łatwiej zarządzać podczas codziennych prac administratora (klonowanie, przywracanie migawek, migracja danych, etc.).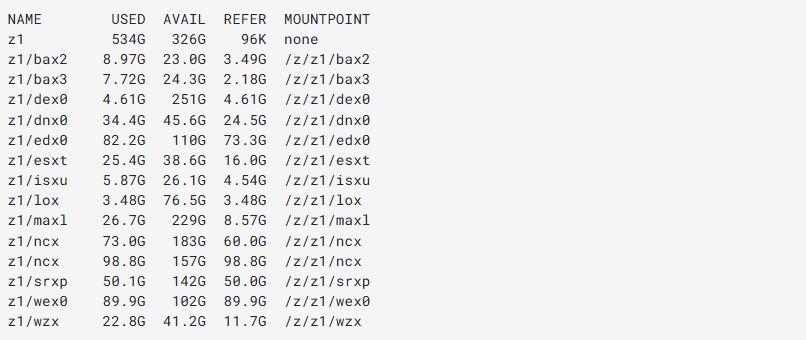
W puli z2 (4 dyski HDD i 2 dyski nvme) utworzone są zasoby podpięte do większości usług. Najczęściej wskazane jako:
[1] 2 urządzenie blokowe,
[2] obraz dysku,
[3] wspólny udział.
W szczególnych sytuacjach [2] wykorzystujemy format obrazów RAW lub bogatszy w funkcjonalności qcow2 mając na uwadze, że ich wydajność może być o ok. 10% niższa od zvol [1] a więc natywnego urządzenia blokowego, które po sformatowaniu i nadaniu mu systemu plików spełnia tą samą funkcjonalność w ZFS.
Wspólny udział [3] wykorzystuje virtiofs https://virtio-fs.gitlab.io/design.html dla danych w obrębie serwera. Dawniej był stosowany Plan 9 Resource Sharing Support (9p2000), lecz sprawdzał się dobrze w lekkich zadaniach.
Pula z2 z 4 dyskami HDD to bardzo zbliżona konstrukcja do RAID10. Różnica polega na wskazaniu pary w mirrorze szybkich dysków do wspomagania operacji odczytu, gdy pamięć RAM stanie się niewystarczająca. Moglibyśmy skorzystać z dobrodziejstw RAID6 (odporność na awarie 2 dowolnych nośników), lecz priorytetem jest większa wydajność.
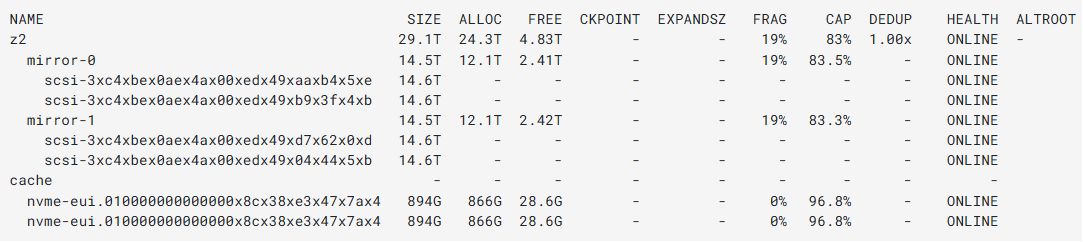
Ostatnia pula z3 to przestrzeń na przechowywanie kopii, która wędrują do innych lokalizacji tj. do kvm108 oraz do HDFS. Priorytet to większa powierzchnia. Odczyt danych nie wpływa na działanie serwera, gdyż ta przestrzeń ma niewielki udział w działaniu usług.

Idea polega na realizacji zadań przywracania danych czy DR (Disaster Recovery). Usługi i ich dane w zależności od awarii są uruchamiane z najbliższego zasobu a kluczową rolę odgrywa czas i jak daleko musimy sięgnąć. Priorytetem jest data locality. Przykładowe scenariusze awarii.
Tuż przed planowanym okienkiem tworzymy snapahota. Po aktualizacji aplikacji / systemu operacyjnego nie otrzymujemy oczekiwanego stanu, zmiany się nie powiodły. Rozwiązaniem jest powrócenie do poprzedniego stan przywracając snapa. Trwa to kilka sekund.
Jedna osoba w pracy kilka dni temu na wspólnym zasobie usunęła plik i wyczyściła kosz. Przywrócenie migawki spowoduje utratę wszystkich zmian, więc z boku montujemy interesującą nas migawkę i wyciągamy zagubiony plik kopiując go na właściwe miejsce np. do katalogu gdzie wcześniej się znajdował. Przeszukanie zasobu zależy od szybkości nośników, w tej sytuacji – przy takiej zajętości przestrzeni dyskowej – polecenie find potrzebuje najczęściej kilku minut.
Różne wypadki się zdarzają, administrator usunął cały zasób (dane i snapshoty, a więc pulę z1 i z2). Przywracamy kopię z z3 włącznie z migawkami, jakie do tej pory przechowywaliśmy. Przywracamy całość streamując kopie na zdefiniowane pule z1 i z2 i to niekoniecznie na tym samym serwerze. Lokalnie pełne przywrócenie 52GB danych trwa niecałe 2 minuty, transfer na poziomie ~1,6TB/h. Przy przesyłaniu danych przez sieć wąskim gardłem może być medium, link na 10Gbps to podstawa1.

W wyniku nieostrożności w naszej sieci pojawiły się na komputerach aplikacje szyfrujące dyski sieciowe. Przywracamy ostatnią niezainfekowaną migawkę (punkt 1) lub przywracamy wybrane pliki (punkt 2).
Pech, został uszkodzony np. backplane skutecznie unieruchomił serwer, aż do przyjazdu technika i wymiany uszkodzonego elementu. Mamy kilka rozwiązań:
– wyjąć dyski i wstawić do innego serwera – tracimy najmniej danych,
– wykorzystać kopię z drugiego serwera, gdyż pula z3 jest cyklicznie synchronizowana z drugim serwerem – tracimy dane od ostatniej synchronizacji,
– na całkowicie nowej maszynie pobrać pliki z HDFS i je zaimportować, last resort – trwa najdłużej.
Podsumowanie
Przedstawiony scenariusz to rozwiązanie efektywne, lecz nie jest uniwersalne. Potrzeby organizacji mogą się skrajnie różnić, posiadać inne wymagania i oczywiście dysponować różnymi środkami zasobów ludzkich i ekonomicznych.
Autorem wpisu jest Marcin Wojtczak – architekt IT, entuzjasta Big Data, Open Source i Security, specjalista od chmur obliczeniowych (AWS, Oracle Cloud, Azure, Alibaba Cloud, GCP), a także ekspert w obszarze DevOps i
DevSecOps. Od kilku lat dzieli się swoją wiedzą jako trener oraz wykładowca akademicki.
Najnowsze komentarze